The client, a global leader in the phone and communications technology sector, was operating with multiple fragmented data systems. While MongoDB Atlas was in use for both structured and semi-structured data storage, the overall data infrastructure lacked cohesion, leading to high operational costs and inefficiencies.
The client’s objective was to streamline their data operations by consolidating both structured and semi-structured data from MongoDB Atlas into Snowflake. This initiative aimed to reduce operational overhead, enable advanced analytics, and improve data accessibility across business units.
– Migrating terabytes of structured and semi-structured data at scale. Handling MongoDB’s BSON format, including nested documents and non-standard data types.
– Aligning flexible schemas with Snowflake’s more rigid relational structure.
– Performing schema mapping and data modeling to preserve data integrity and utility.
– Developing a dynamic and reusable ETL framework for repeatable, scalable migration tasks.
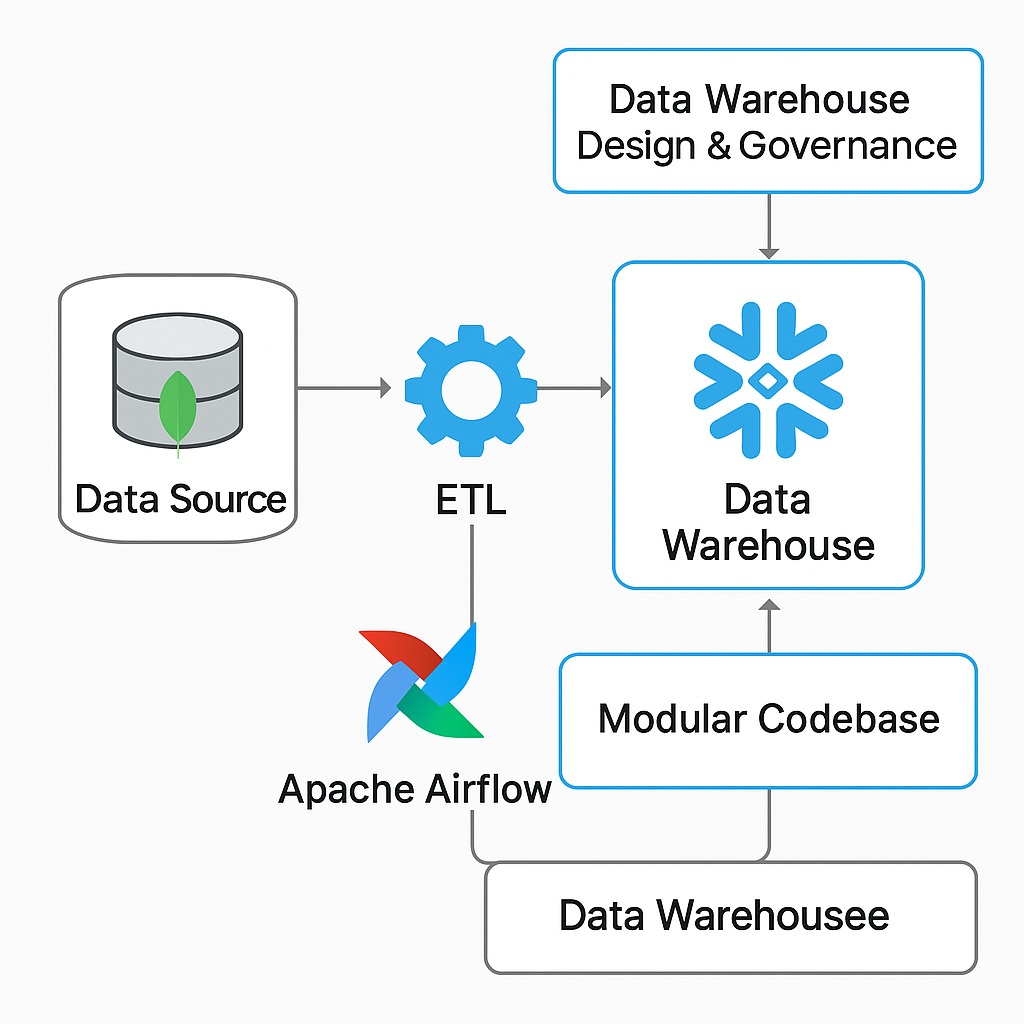
Our Data Engineering consulting team architected and led the end-to-end migration strategy using Apache Airflow and Python. Key elements of the solution included:
– Implemented a phased migration approach to validate each stage before scaling.
– Developed automated Airflow pipelines for data extraction, transformation, and loading (ETL).
– Used Python scripts to normalize and transform structured and semi-structured data, handling arrays, nested fields, and custom types.
– Leveraged Airflow logs for monitoring, issue tracking, and performance optimization.
– Conducted iterative optimization to enhance pipeline efficiency and reliability over time.
In addition to data migration, our team was responsible for designing the Snowflake data warehouse layout, establishing scalable and secure data architecture practices.
Key components of the design included:
– Database & Schema Design: Created logical separation for environments and business domains, including development, staging, and production databases.
– Schema Definitions: Established schemas for landing (staging), operational, and analytics layers .
– Secure Role-Based Access Control: Defined roles for analysts, engineers, and admins (e.g., ANALYST_READ, ENGINEER_WRITE, SYSADMIN). Granted privileges based on least-privilege principles
– Warehouse Design: Provisioned Snowflake virtual warehouses sized appropriately for ETL and reporting workloads, using separate compute clusters for ingestion and analytics.
This layered architecture ensured clean separation of concerns, high query performance, and secure data consumption across business units.
To ensure scalability and maintainability, we built a configuration-driven, modular codebase:
– Dynamic DAG Generation: Automatically created DAGs based on configuration inputs, allowing rapid deployment of new pipelines.
– Parameterized Tasks: Enabled reusable tasks with runtime parameter support for diverse migration jobs.
– Custom Operators and Hooks: Built abstractions for handling data interaction and transformation logic.
– Centralized Configuration Management: Controlled schema mapping, connection settings, and pipeline behaviors from a single source.
– Separation of Concerns: Maintained clean layers between logic, orchestration, and configuration files.
– Reduced infrastructure and operational costs by consolidating data platforms.
– Enabled faster rollout of new data migrations through reusable pipelines.
– Improved data consistency, availability, and readiness for analytics.
– Delivered a scalable foundation for future structured and semi-structured data integration.
– Data Source: MongoDB Atlas (Structured & Semi-Structured Data)
– Data Warehouse: Snowflake
– Orchestration: Apache Airflow
– Programming Language: Python
– Monitoring & Logging: Airflow Logs
This project successfully unified a fragmented data environment into a scalable and efficient architecture. By developing a modular and configuration-driven pipeline capable of handling both structured and semi-structured data, the migration not only solved immediate challenges but also provided a future-proof foundation for ongoing data integration efforts.