The client is a global executive search and leadership advisory firm offering a suite of talent intelligence products and assessments. Their digital platform collects leadership assessment data from both internal and external systems, helping organizations make informed decisions for executive placement and leadership development.
The client needed a centralized, reliable, and scalable data pipeline to process large volumes of leadership assessment data from disparate sources. Data was arriving in both structured and semi-structured formats, and the existing system lacked efficiency in transforming and analyzing this data in a way that supported business intelligence and executive reporting needs.
– Data Complexity: Data included both structured records (e.g., scores, timestamps) and deeply nested semi-structured JSON (e.g., answers, behavior metrics).
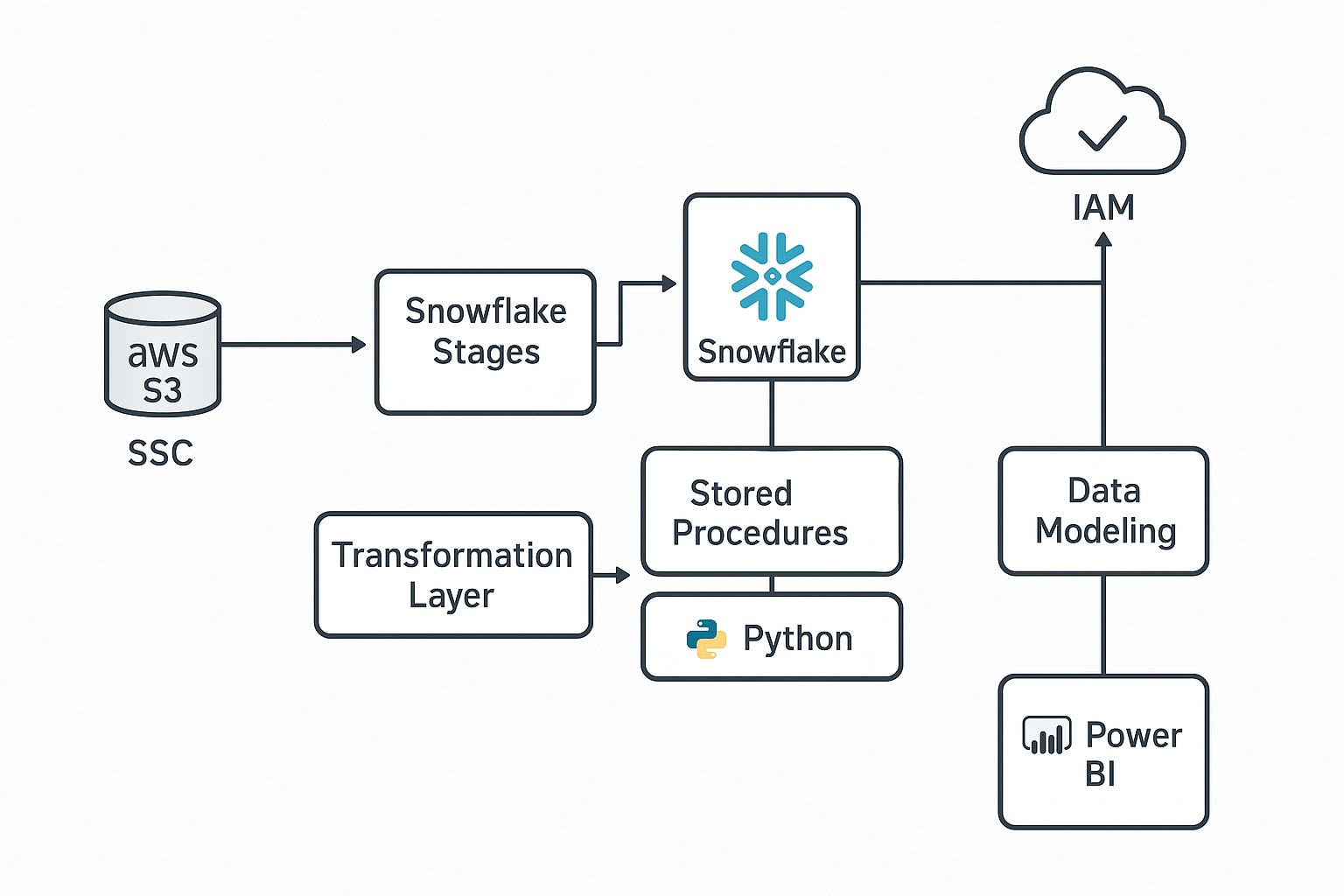
– Data Ingestion: Data was stored in AWS S3 in various formats and needed transformation before consumption.
– Transformation Logic: Data needed heavy normalization, including flattening nested fields and aligning schemas across tools.
– Performance & Maintainability: Initial workflows required frequent manual updates and lacked modularity.
Our data engineering team designed and implemented a scalable, automated data pipeline to process assessment data efficiently and reliably.
Staging Layer:
– Data from multiple sources (e.g., S3) was first loaded into Snowflake using internal stages.
– Staging tables were used to hold raw data for further transformation.
Transformation Layer:
– We developed a series of Snowflake stored procedures and Python scripts to handle:
– JSON parsing and flattening
– Data type coercion
– Schema standardization
– Filtering and validation logic
– This layer transformed raw input into clean, normalized tables.
Data Modeling Layer:
– Data was loaded into dimension and fact tables aligned with a star schema, ensuring efficient querying and reporting.
– we were responsible for designing the data warehouse layout including database, schema structure, naming conventions, and relationships.
– Internal Stages: Used for staging semi-structured files directly from S3.
– VARIANT Columns: Allowed ingestion of JSON data for intermediate processing.
– Stored Procedures & Tasks: Automated and orchestrated data transformation workflows.
– Role-Based Access Control (RBAC): Ensured secure, granular data access across teams.
To enable maintainability and future scalability:
– We built reusable Python modules for transformation and validation.
– Snowflake stored procedures were parameterized to handle varying table structures.
– Logging and exception handling were built into both Python and SQL logic for traceability.
– Faster Data Processing: Reduced data transformation time by 60%.
– Improved Data Quality: Standardized schemas and centralized logic improved the trustworthiness of insights.
– Automation: Reduced manual effort and allowed analysts to focus on insights rather than data cleanup.
– Real-Time Insights: Enabled Power BI dashboards to serve leadership insights with refreshed, curated data.
– Cloud: AWS (S3, IAM)
– Data Warehouse: Snowflake
– Processing: Python, Snowflake Stored Procedures
– Data Ingestion: Snowflake Stages
– Orchestration: Snowflake tasks
– BI Tool: Power BI
The pipeline now serves as the foundation for leadership analytics, executive search support, and behavioral insights. Future enhancements could include:
– Real-time ingestion for live assessments
– Data quality monitoring via automated alerts
– Machine learning models for leadership trait prediction